

Spark on OCI Workload Brief
Jun 2022 Big Data Spark on Oracle Cloud Ampere A1 instance
Ampere - Empowering What’s Next
Oracle Cloud Infrastructure (OCI) offers Ampere® Altra® compute instances on the new Cloud Native Ampere A1 platform. The Ampere A1 platform can be deployed as bare metal servers or flexible VM shapes, giving customers full control of their entire cloud stack. The Ampere A1 VM shapes provide flexible sizing from 1-80 cores and 1-64 GB of memory per core, along with several key benefits such as deterministic performance, linear scalability, and a secure architecture with the best price-performance in the market.
Apache Spark is an open source, distributed processing system used for big data workloads. It utilizes in-memory caching, and optimized query execution for fast analytic queries against data of any size. It provides APIs in Java, Scala, & Python. Spark supports multiple operations in real time analytics, batch processing, interactive queries, and machine learning. Spark addresses the limitations of Hadoop by doing in-memory processing using RDD (Resilient Distributed Dataset) and reusing data across multiple parallel operations. Spark works with many storage systems like HDFS, Couchbase, Cassandra and others.
Spark can run in a standalone cluster mode or on Cluster Management systems like Yarn, Kubernetes and Docker.
Spark architecture consists of the Spark driver, executor and cluster manager. The driver is the controller of the Spark execution engine and maintains the state of the cluster. It interacts with the cluster manager to get physical resources like vCPU and memory. The driver also launches the executors. Actual tasks are processed by the Spark executors assigned by the driver. The executors run the tasks and report back their results and state to the driver. The cluster manager is responsible for maintaining the cluster of nodes that run the Spark applications.
Spark on OCI Ampere® A1 Flex VM
OCI’s A1 compute provides superior price-performance for big data applications when compared to its x86 peers. A1 shapes with Ampere Arm processors are a recommended choice for Spark applications due to the predictable and highly scalable nature of the architecture.
Oracle Cloud Infrastructure uses Ampere Altra processors with industry leading 80 cores per CPU for the Ampere Altra A1 shapes All cores are capable of running at the maximum frequency of 3.0 Ghz consistently. Utilizing Ampere Altra low power design and OCI’s high performance infrastructure, Ampere A1 shapes deliver the best price-performance in the cloud.
In this solution brief, the performance of OCI Ampere A1 VM’s is compared with OCI’s S3 Standard (Intel icelake), E3 (AMD Rome) and E4 (AMD Milan) flex VM’s. The following benchmarks/tests were run on Spark with yarn.
1. Spark TeraSort 2. Join operations 3. Word count 4. TPC-DS
Key benefits of Spark on OCI
Consistency and Predictability: Ampere Altra processors are designed for cloud native usage, providing consistent and predictable performance for Hadoop solutions.
Scalable: With an innovative scale-out architecture, Ampere Altra processor’s high core count and compelling single-threaded performance combined with consistent frequency on all cores delivers up to 20% better performance for Spark operations.
Power Efficient: Industry-leading energy efficiency allows Ampere Altra processors to hit competitive levels of raw performance while consuming much lower power than the competition often resulting in lower costs for Ampere based shapes.
Ampere Altra
- 80 64-bit CPU cores up to 3.00 GHz
- 64 KB L1 I-cache, 64 KB L1 D-cache per core
- 1 MB L2 cache per core
- 32 MB System Level Cache (SLC)
- 2x full-width (128b) SIMD
- Coherent mesh-based interconnect
Memory
- 8x 72-bit DDR4-3200 channels
- ECC and DDR4 RAS
- Up to 16 DIMMs and 4 TB addressable memory
Connectivity
- 128 lanes of PCIe Gen4
- Coherent multi-socket support
- 4 x16 CCIX lanes
Technology & Functionality
- Arm v8.2+, SBSA Level 4
- Advanced Power Management
Performance
- SPECrate®2017 Integer Estimated: 300
Spark on OCI Architecture
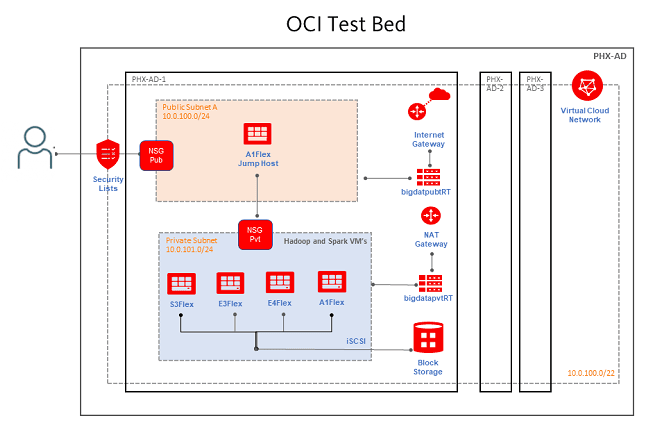
Benchmarking Configuration
Virtual machines were provisioned in a private network space as depicted above. Hadoop 3.3.1 (aarch64 binaries) and Spark 3.1.2 were installed on the test bed.
- A single VM was spun across each of the architectures with the configuration as outlined in the table.
- All the virtual machines had identical configurations of CPU cores/threads, memory and storage.
- The storage bandwidth was limited to 1000 MB/s across all the VM’s. The maximum bandwidth for an x86 VM with 8 OCPU’s is 8 Gb/s in OCI. An A1 instance with 16 OCPU’s receives a max bandwidth of 16 Gb/s. The A1 Instance was throttled to 8 Gb/s in our benchmark, to keep it at par with x86 VM’s. -Very few changes like disabling transparent huge pages and, reducing VM swappiness were altered on the guest Operating system.
- Few configuration parameters in Spark were tuned to maximize the utilization of CPU, memory and storage.
- Oracle JDK8 EPP was used on the test bed. This patch 34375301 can be downloaded from Oracle support site. JDK 17 improvements are added to Oracle JDK 8 EPP (enterprise performance pack).
VM and Spark on Yarn Configuration
| S3Flex | E3Flex | E4Flex | A1Flex | |
|---|---|---|---|---|
| OCPU | 8 | 8 | 8 | 16 |
| Cores/Threads | 8/16 | 8/16 | 8/16 | 16/16 |
| Mem | 96G | 96G | 96G | 96G |
| Arch | x86_64 | x86_64 | x86_64 | aarch64 |
| Kernel | Oracle Linux 8.5 |
| Storage | iSCSi 2 x 500G luns, VPU 50, 2 x 480 MBPS |
| JDK | JDK8 EPP |
Spark and Yarn Configuration
| dfs.block.size | 256M |
| yarn.scheduler.minimum-allocation-mb | 1024 |
| yarn.scheduler.maximum-allocation-mb | 65536 |
| yarn.scheduler.minimum-allocation-vcores | 1 |
| yarn.scheduler.maximum-allocation-vcores | 15 |
| yarn.nodemanager.resource.cpu-vcores | 16 |
| yarn.nodemanager.resource.memory-mb | 94208 |
| mapreduce.map.memory.mb | 1024 |
| mapreduce.reduce.memory.mb | 3072M |
| mapred.reduce.parallel.copies | 16 |
| mapreduce.reduce.shuffle.parallelcopies | 16 |
| mapreduce.map.java.opts | 2048M |
| spark master | yarn |
| spark.executor.memory | 12G |
| spark.default.parallelism | 30 |
Benchmark
Spark TeraSort
The TeraSort workload sorts 100-byte records generated by the TeraGen program contained in the Hadoop distribution. The Intel HiBench benchmark tool was used on each of the VM’s to generate a 250GB dataset. Spark TeraSort benchmark was run on these VM’s and the TeraSort output in MB/s was captured.
Join Operations
The following scala query was executed multiple times in Spark shell to capture the time taken to complete the join query.
val df = sc.makeRDD(1 to 10000000, 7).toDF val df2 = sc.makeRDD(1 to 10000000, 7).toDF df.select( $"value" as "a").join(df2.select($"value" as "b"), $"a" === $"b").count
Word Count
Word Count programs are representative of a large subset of real-world MapReduce jobs, one transforming data from one representation to another and another extracting a small amount of interesting data from a large data set. Uploaded 10GB of text file to HDFS and then attempted to count the words in the file.
TPC-DS
TPC-DS is a decision support benchmark that models several aspects of a decision support system. The tpcds-kit was cloned from databricks github site. Spark 3.2 was run in yarn mode with a scale factor of 250 and in parquet format. The time taken to execute all the 99 sql statements were captured.
Performance Data
The relative performance data captured on OCI test bed with Spark on Yarn is shown below.
The relative price per performance data captured with Spark TeraSort is shown below. Similar graphs for other benchmarks and tests like Wordcount and Join operations can be plotted by taking the prices from compute and storage pricing.
Observations
1. After tuning the parameters, CPU was fully utilized and was hovering around 85-90% making this a fair comparison under high load conditions. 2. A1 VM’s performed well compared to its x86 peers. The performance graphs were plotted by taking s3flex as the baseline reference point. 3. Ampere A1 instances price performance was observed to be 50% better than Intel and 30% better over AMD shapes.
Note: Price-performance was calculated from OCI Compute pricing list, for 16 core VM’s and 96G Memory (Oct 2022). Storage Costs were calculated from OCI Storage pricing sheet for 2x500GB iSCSI luns at 50 VPU ( 480 MB/s).
Conclusions
Oracle OCI A1 instances with Ampere Altra processors provide high performance for big data solutions like Spark. The performance advantage on the Ampere instances combined with the price advantage provides up to 50% higher value when using OCI Ampere A1 instances for Spark TeraSort and TPCDS workloads.
For More Information
Footnotes
All data and information contained herein is for informational purposes only and Ampere reserves the right to change it without notice. This document may contain technical inaccuracies, omissions and typographical errors, and Ampere is under no obligation to update or correct this information. Ampere makes no representations or warranties of any kind, including but not limited to express or implied guarantees of noninfringement, merchantability, or fitness for a particular purpose, and assumes no liability of any kind. All information is provided “AS IS.” This document is not an offer or a binding commitment by Ampere. Use of the products contemplated herein requires the subsequent negotiation and execution of a definitive agreement or is subject to Ampere’s Terms and Conditions for the Sale of Goods.
System configurations, components, software versions, and testing environments that differ from those used in Ampere’s tests may result in different measurements than those obtained by Ampere.
Price performance was calculated from OCI Compute pricing list, for A1 Flex VMs in March of 2022. Refer to individual tests for core counts. Memory and Storage is same across all the VM’s, and hence not considered
©2022 Ampere Computing. All Rights Reserved. Ampere, Ampere Computing, Altra and the ‘A’ logo are all registered trademarks or trademarks of Ampere Computing. Arm is a registered trademark of Arm Limited (or its subsidiaries). All other product names used in this publication are for identification purposes only and may be trademarks of their respective companies.
Ampere Computing® / 4655 Great America Parkway, Suite 601 / Santa Clara, CA 95054 / amperecomputing.com
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



