

Hadoop Workload Brief
with Ampere Altra Max Processors
Greater Efficiency on Hadoop with Ampere Altra Max Processors
This solution brief presents an analysis of several benchmarks performed on Big Data Hadoop using Altra® Max® processors when compared to x86 processors. The benchmarks include Hadoop TeraSort and Hadoop Wordcount, featuring power and performance metrics as well as rack-level efficiency in a datacenter.
We observed that servers with Ampere processors achieved a 25% improvement in raw TeraSort throughput and they delivered more than 50% Performance/Watt (Perf/Watt) improvement over x86. This translates to a reduction in the number of racks required to run Big Data services such as Hadoop at scale. Using fewer racks, the total datacenter footprint is reduced, resulting in fewer infrastructure components such as servers, switches, and cables. As a result, there is a reduction in square footage, cooling, water, and other supporting resources, enabling datacenter operations to achieve their PUE (Power Usage Effectiveness and other SLA (Service Level Agreement) objectives.
Hadoop with Ampere Altra and Altra Max processors
Ampere’s SOC family is designed to provide more cores per socket, thus maximizing the number of cores per rack. Clusters utilizing Ampere Altra processors benefit from a power-optimized design that enables lower power consumption and predictable performance for big data applications and other data lake technologies. Also, the processors are designed to deliver exceptional energy efficiency, resulting in industry-leading Perf/Watt at the individual server level and Performance per Rack (Perf/Rack) at scale. This not only reduces operating costs but also results in a significantly lower carbon footprint.
Apache’s Hadoop framework is designed for distributed processing of large data sets. Hadoop is designed to scale out from a single server to hundreds of machines, each offering local computation, storage, or both. When implemented in clusters, the software’s built-in resiliency to handle failed servers or components delivers top-notch availability. Hadoop clusters multiple compute nodes to analyze data in parallel. It consists of four main modules:
- HDFS (Hadoop Distributed File System)
- YARN (Yet Another Resource Negotiator)
- Map Reduce (MapR)
- Hadoop Common
Benchmarking Configuration
We used HiBench tool to assess the performance and scalability of Hadoop on two three-node clusters, one equipped with Ampere Altra Max processors and the other with Intel Ice Lake processors. HiBench is a comprehensive big data benchmark suite designed to evaluate different big data frameworks in terms of speed, throughput, and system resource utilization. It provides a set of macro and micro benchmarks that help measure the performance of big data processing systems under various conditions.
Equipment Under Test
| Architecture | Ampere Altra Max | Intel Ice Lake |
|---|---|---|
| Make & Model | HPE RL300 | Dell PowerEdge R650 |
| Cluster Nodes | 3 | 3 |
| CPU | Ampere M128-30 | Intel Ice Lake Xeon SP 6342 |
| Sockets/Node | 1 | 2 |
| Cores/Socket | 128 | 24 |
| Threads/Socket | 128 | 48 |
| CPU Speed | 3.0 GHz | 2.8 GHz |
| Memory | 512GB | 512GB |
| Network Card | 1 x Mellanox CD-6 Dx | 1 x Mellanox CX-6 Dx |
| Storage | 4 x Micron 7450 Gen 4 NVME | 4 x ScaleFlux CSD 3010 Gen 4 NVME |
| Kernel Version | 4.18.0-348.7.1 | 5.15.0-60-generic |
| Operating System | CentOS 8.5 | Ubuntu 22.04 LTS |
| Hadoop Version | 3.3.4 | 3.3.4 |
Performance tests on a 3 Node cluster (Ampere Altra Max and Intel Ice Lake processors)
We set up two clusters consisting of three nodes each. To compare the performance of the clusters, we used Dell PowerEdge R650 servers with Intel Ice Lake processors and HP RL300 with Altra Max processors. Both clusters ran Hadoop version 3.3.4. Throughput from the cluster was captured using HiBench for TeraSort and Wordcount benchmarks on these clusters, each using a data set of 3 TB.
We collected the throughput from HiBench tool, for TeraSort and Wordcount, while the total power consumed by each cluster was measured using IPMI and Redfish tools.
When running the TeraSort and Wordcount benchmarks on the clusters, we observed that the TeraSort throughput was 24% higher and the Wordcount throughput was 48% higher on the Altra Max systems compared to the Intel Ice Lake systems. To measure the energy efficiency of each cluster, we calculated the Perf/Watt ratio by dividing cluster throughput (MBPS) by cluster power consumed (watts) during the benchmarking interval. The Altra Max cluster was found to be 85% better with TeraSort and 2x better with Wordcount than the Intel Ice Lake cluster in terms of Perf/Watt.
Simulated Hadoop TeraSort at Rack Level
We extended the 3-node cluster data (42U with 12kW power budget, leaving room for network and other equipment) to calculate performance efficiency at the rack level. We found that the HPE RL300 servers with Altra Max processors delivered a 55% higher TeraSort throughput compared to Dell PowerEdge R650 servers with Intel Ice Lake processors under the same power budget. In addition, to achieve the same TeraSort throughput, Intel Ice Lake systems required 44% more rack space than Altra Max systems.
Key Findings and Conclusions
Processing Big Data using services such as Hadoop may require hundreds of servers based on your data set. Therefore, it is essential for the infrastructure to be scalable while also maintaining sustainable performance.
Our benchmarking efforts indicate that Ampere’s Altra Max CPUs not only offer superior performance, but also consume less power, thus reducing the number of required Ampere racks over x86 racks, to deliver the same performance. Specifically, 23 Ampere Altra Max CPUs can deliver comparable performance to 50 Intel Ice Lake CPUs. This translates to a significant power savings of 57% with the use of Altra Max servers compared to Intel for Hadoop workloads.
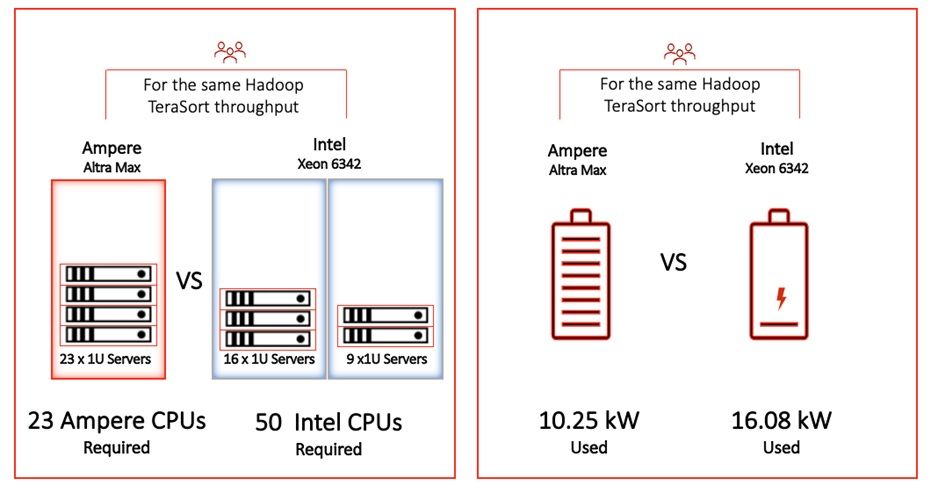
Ampere’s architecture is significantly more sustainable and can reduce the overall resource footprint of Hadoop deployments by over 50%. This kind of advantage is truly disruptive, making the Ampere Altra family the most sustainable processor for your on-premises and cloud deployments.
About Ampere and Hadoop on Ampere processors
The key benefits of running Hadoop on Ampere Altra Max processors are:
-
Increase Throughput: Based on the type of workload, Ampere Cloud Native Processors running Hadoop exhibit a 20-50% improvement in throughput compared to legacy x86 servers.
-
Conserve Rack Space: Ampere Altra Max's combination of performance and power efficiency enables exceptional performance per rack, especially for high-demand workloads like Hadoop. Our observations showed that x86 systems required 44% more rack space to deliver the same throughput as Altra Max.
-
Lower Power Consumption: By leveraging the inherent benefits of lower power consumption and higher core count of Ampere Altra Max Cloud Native Processors, it is possible to achieve greater scalability with fewer CPUs, fewer racks, and lower power consumption. In the study conducted, a 57% power savings was observed compared to traditional x86 servers.
Footnotes
As part of performance benchmarking, we observed run to run variations in the measured throughput. In order to minimize the effects of these variations, we ran each test 3 times and used the geomean of the measured throughput in MBPS and power consumption in watts for our final calculations.
Disclaimer: All data and information contained in or disclosed by this document are for informational purposes only and are subject to change. This document may contain technical inaccuracies, omissions and typographical errors, and Ampere Computing LLC, and its affiliates (“Ampere”), is under no obligation to update or otherwise correct this information. Ampere makes no representations or warranties of any kind, including express or implied guarantees of noninfringement, merchantability or fitness for a particular purpose, regarding the information contained in this document and assumes no liability of any kind. Ampere is not responsible for any errors or omissions in this information or for the results obtained from the use of this information. All information in this presentation is provided “as is”, with no guarantee of completeness, accuracy, or timeliness.
Related Content
Ampere Computing LLC
4655 Great America Parkway Suite 601
Santa Clara, CA 95054



